It is strongly recommended to first make a backup !!!
Go to My Profile – Specimen Management – Collection Management – click “Your Collection Name”
In the Administration Control Panel choose Import/Update Specimen Records:

A choice of several options appears.
If this is a one-time batch upload from a CSV, choose Full-Text File Import:
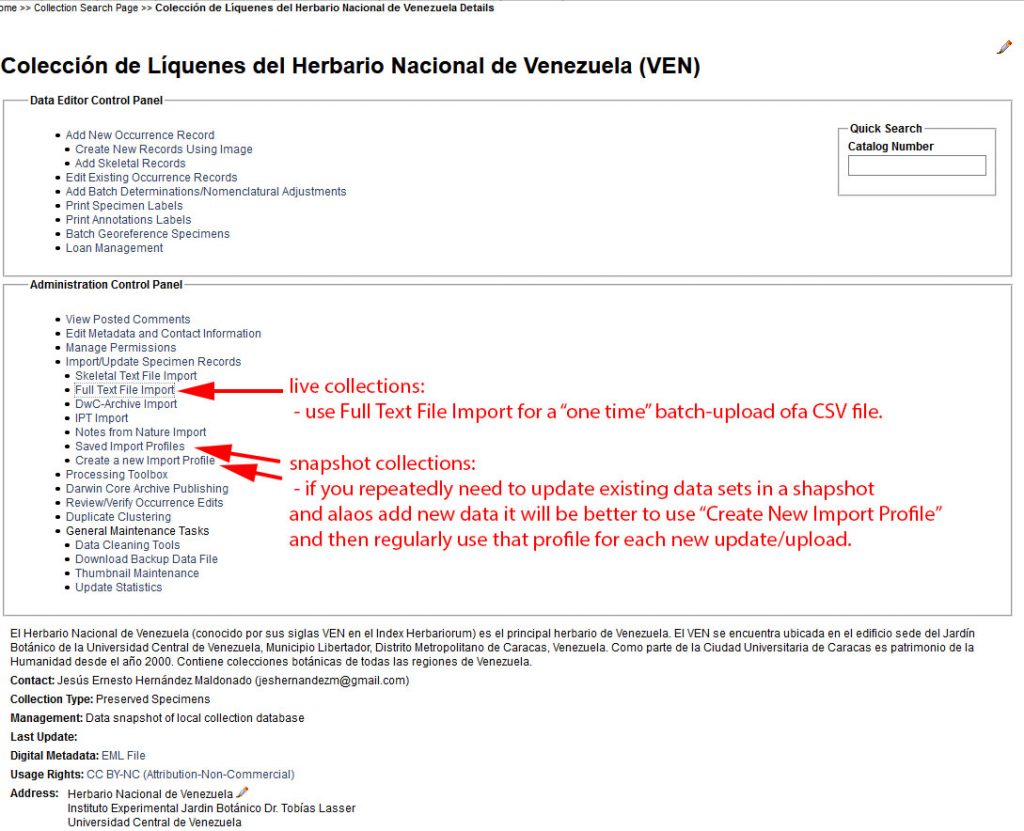
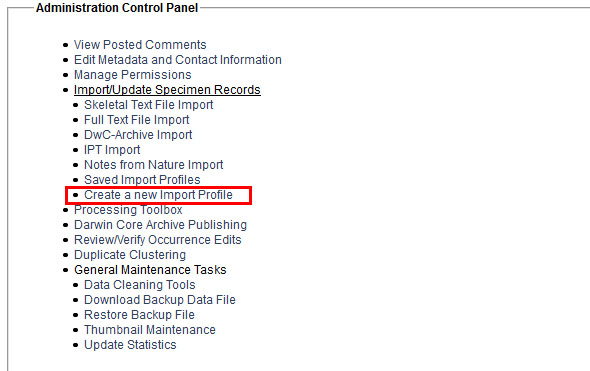
However, if you ever plan to do a similar upload again it is generally better to create a New Profile:
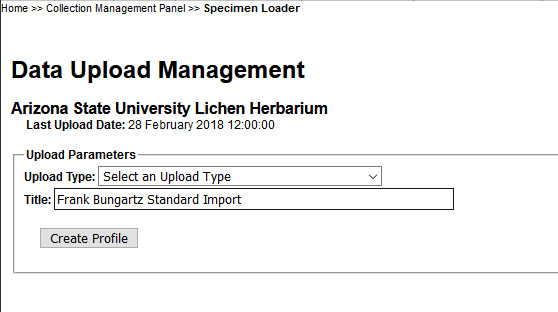
Choose an appropriate name:
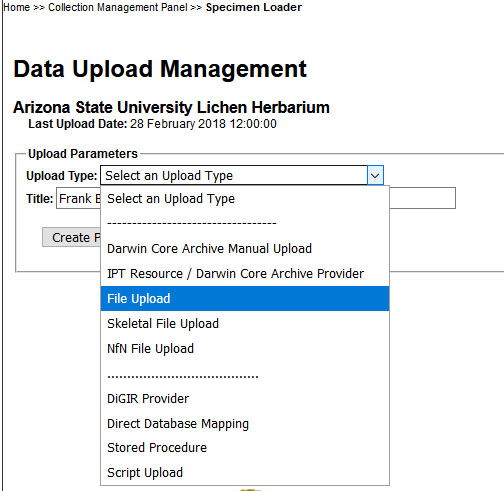
The most common scenario is uploading a flat file (in CSV format):
If you previously created other profiles, you can select the saved profile from a list:
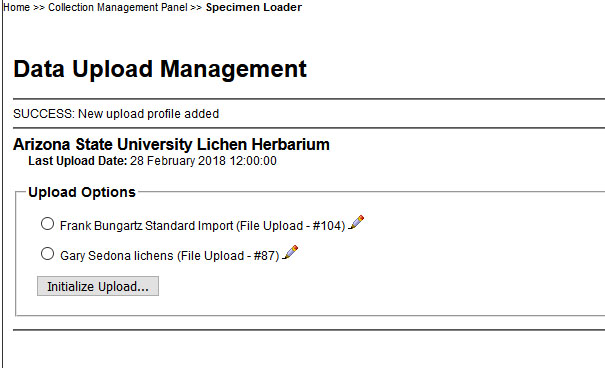
In the Data Upload Module choose the CSV file that you want to upload:

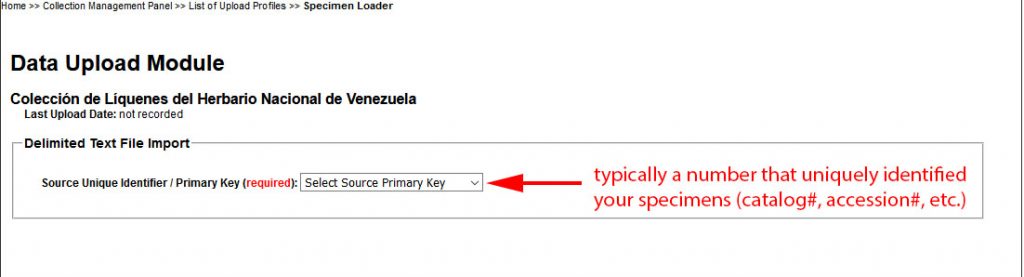
You will need to select one field that uniquely identifies each record (e.g., the catalog number) as the primary key:
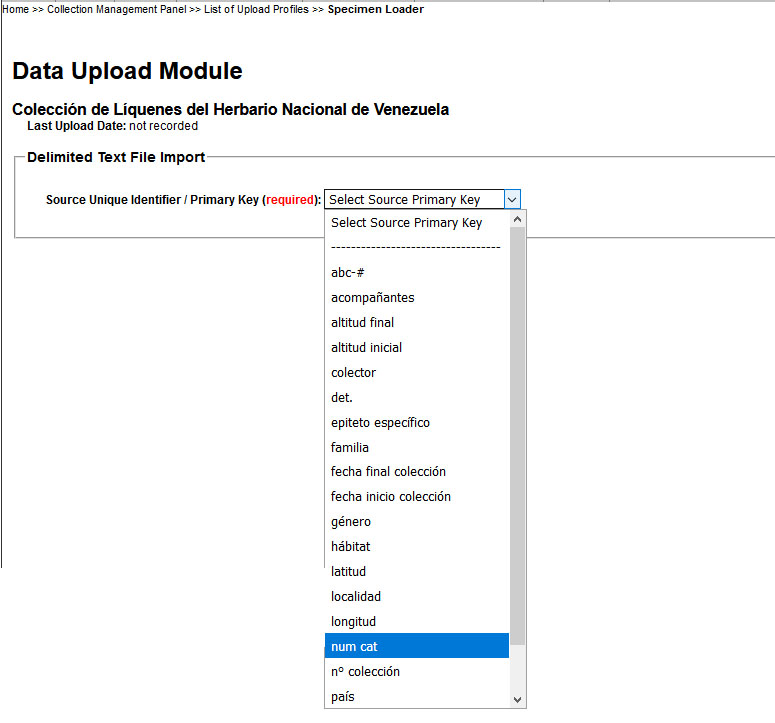
Now you are ready to map fields in your spreadsheet to the standard Darwin Core fields used in CNALH:
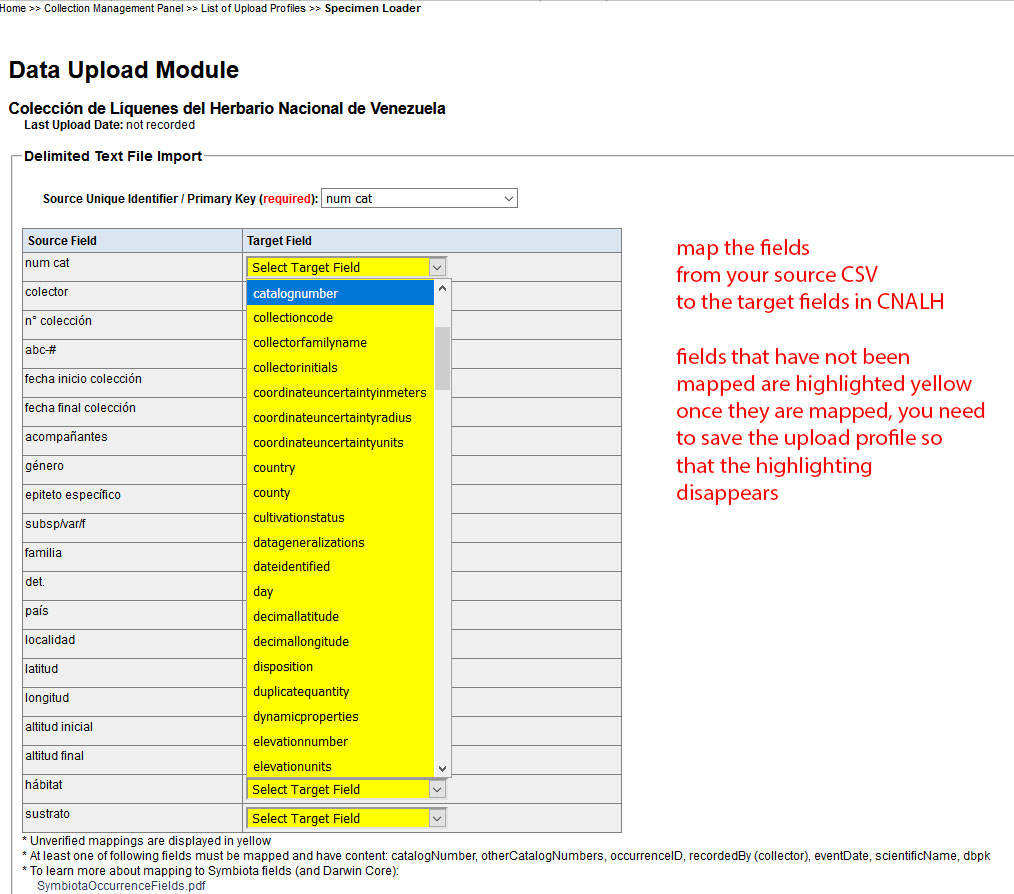
During the process you can successively save the mapping to your upload profile. Fields already mapped no longer appear highlighted. If you chose not to create an upload profile, but now decide that you would like to save one, add a profile name:
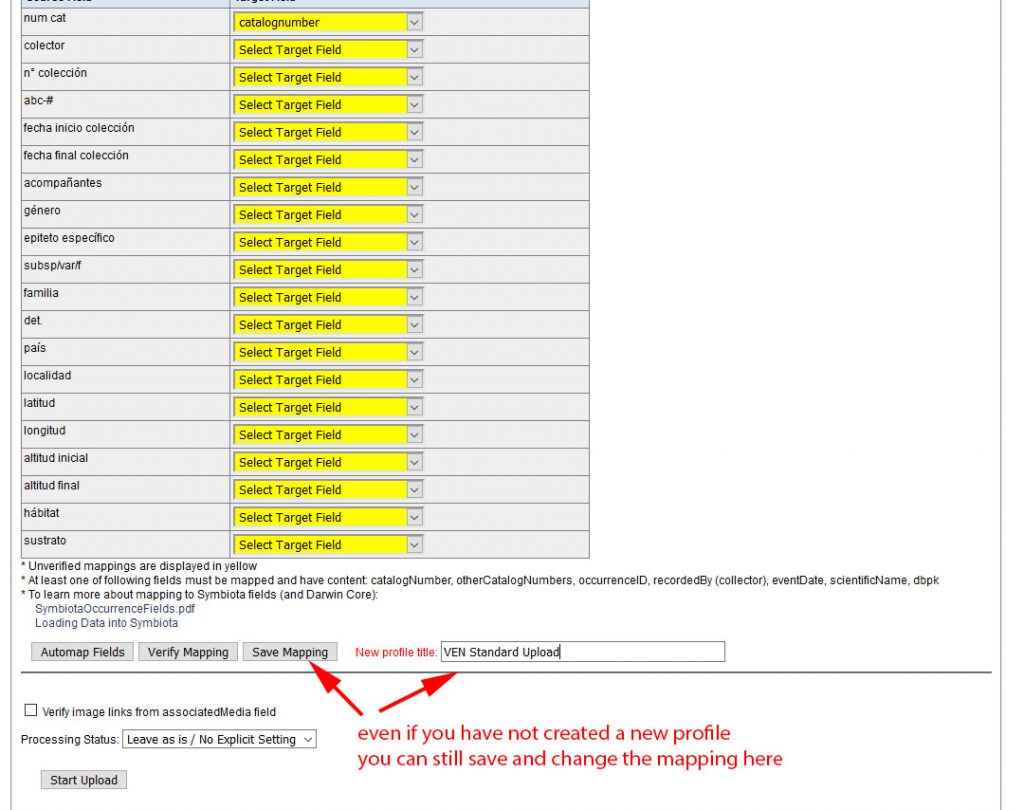
Download the SymbiotaOccurenceFields.pdf for more information how the Darwin Core fields are defined.
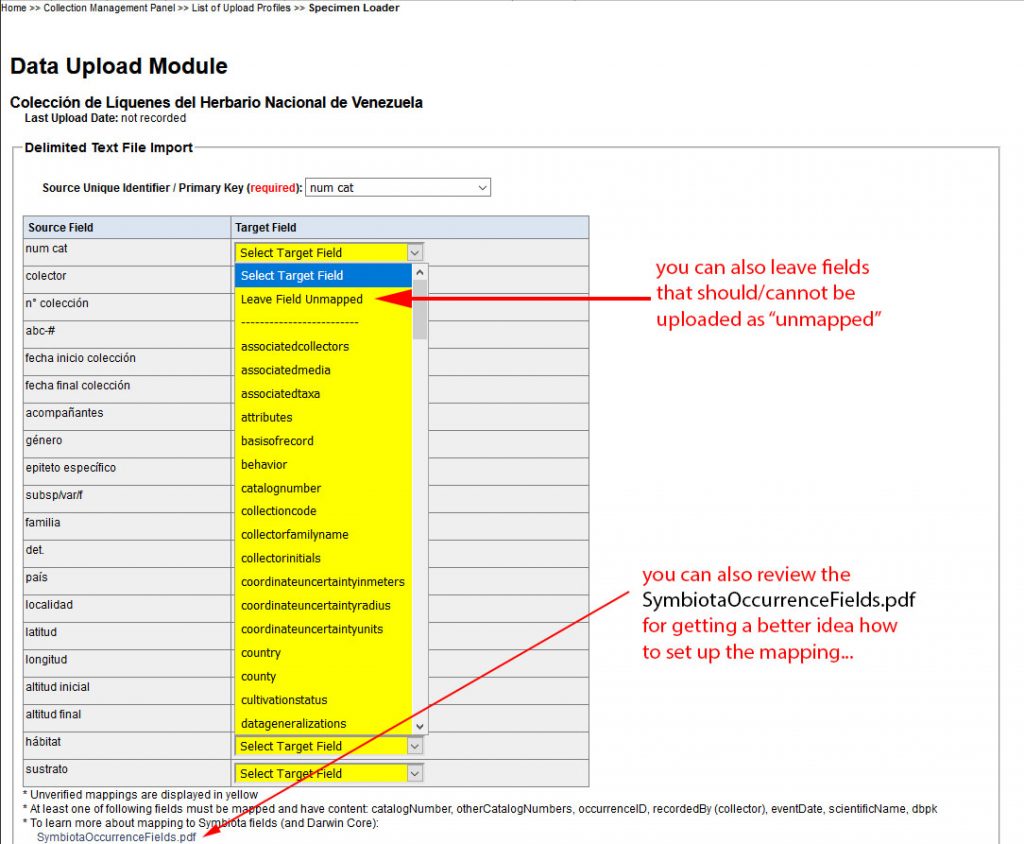
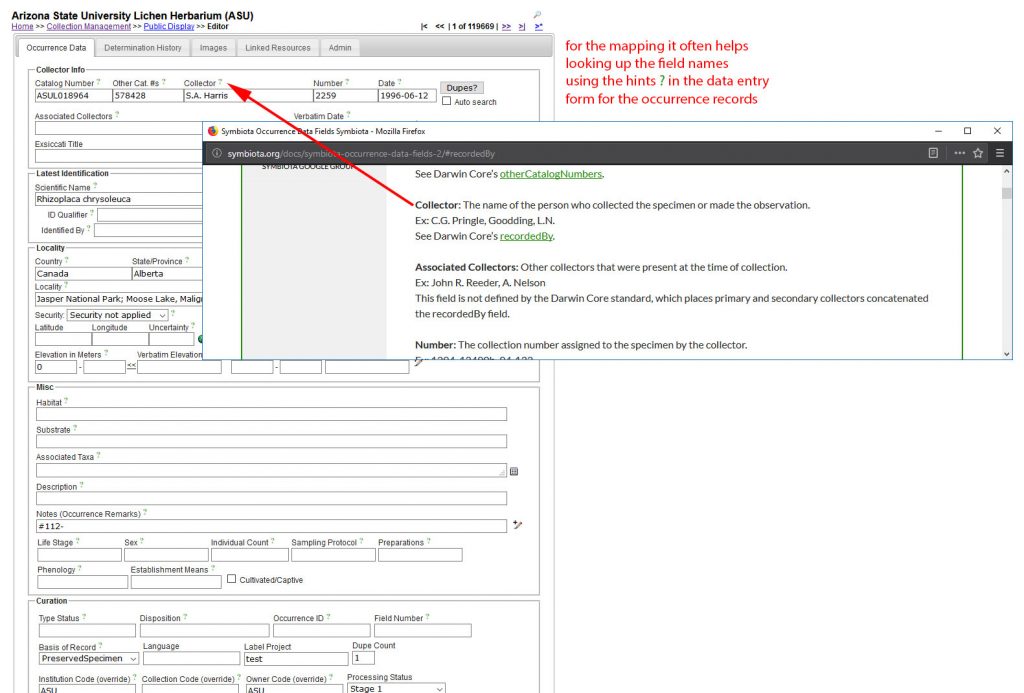
Or have a look on the field definitions in an existing collection:
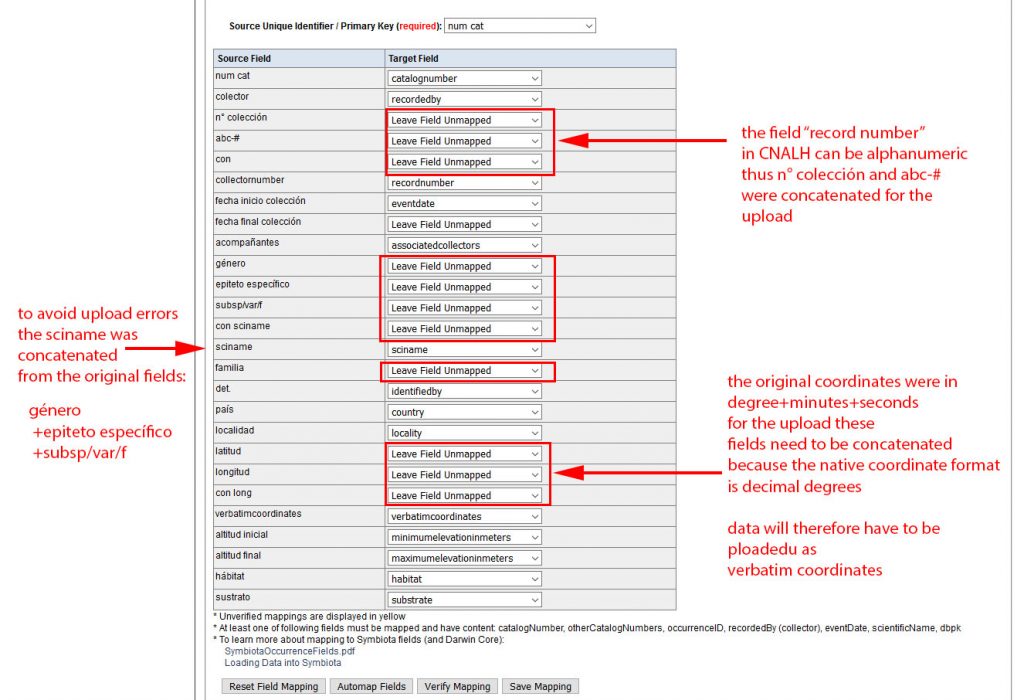
Even though the mapping is very powerful, not all spreadsheets can directly be uploaded. Sometimes the original data needs to be modified to conform to the way how the Darwin Core fields are defined:
When you are done with the mapping, review the fields and click upload:
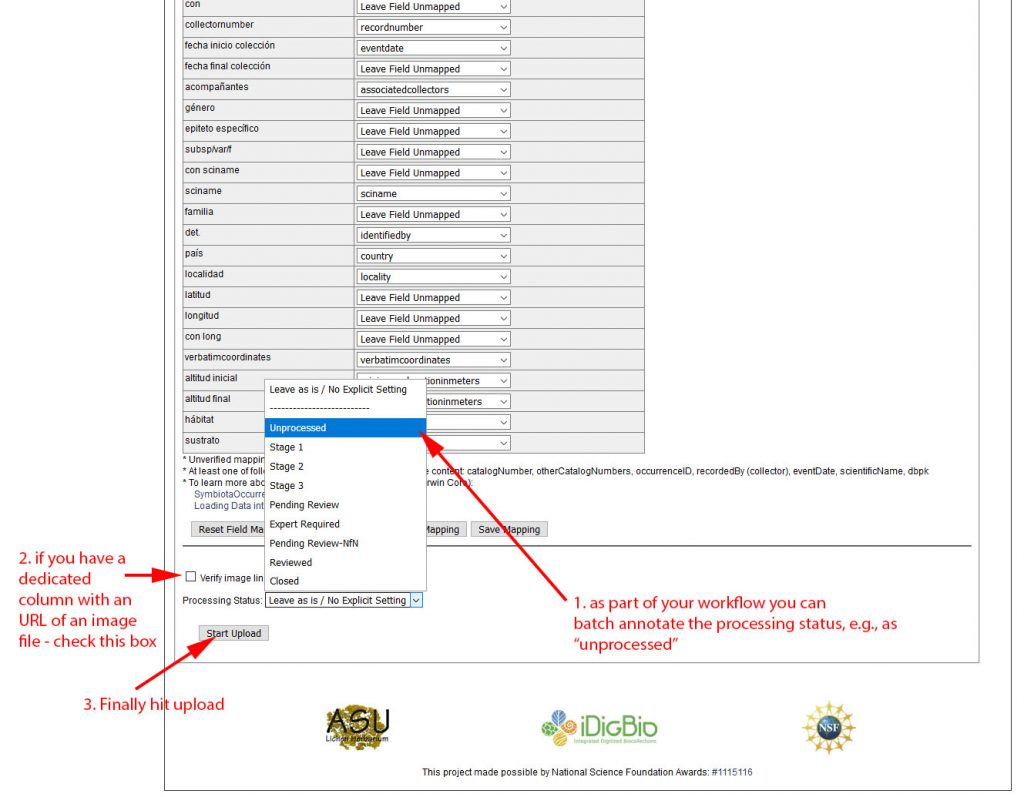
Before the final upload is executed, data will be stored in a temporary transfer table:

Review that there are no errors before you transfer the data into the main collections table:
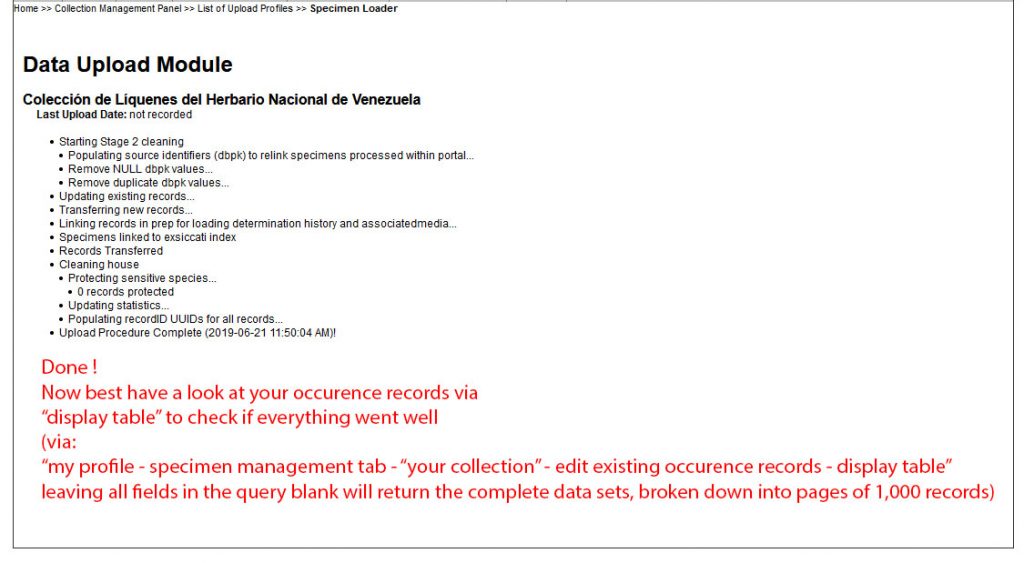
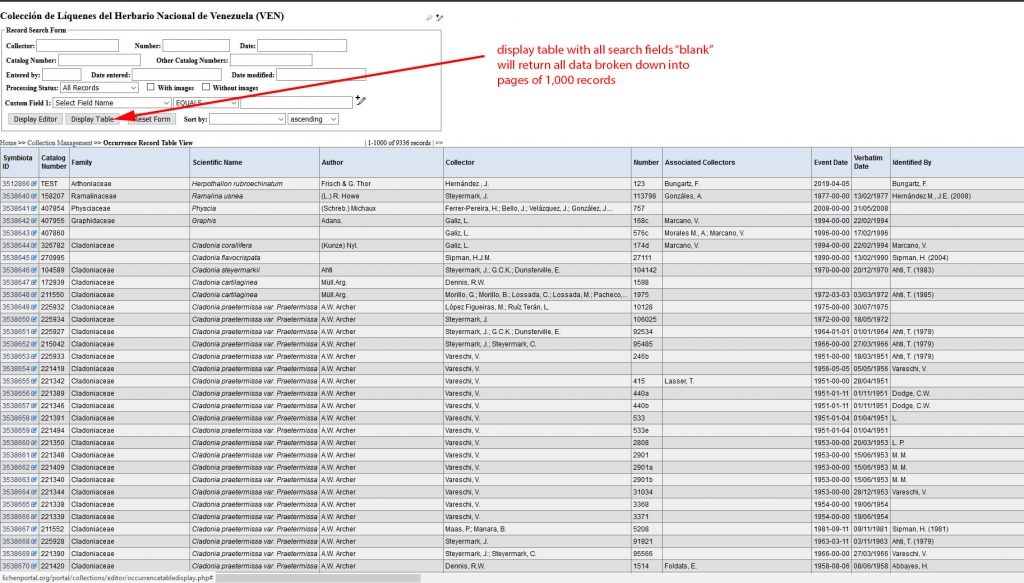
Via My Profile – Specimen Management – “your collection name” – Edit Existing Occurrence Records – Display Table you may now want to review if the data uploaded correctly:
Depending how some fields were uploaded, not all data may have been available and those fields are thus empty. In our example GPS coordinates were uploaded to the Verbatim Coordinates field and still need to be parsed into Decimal Coordinates, which the system natively uses to display distribution records on maps:
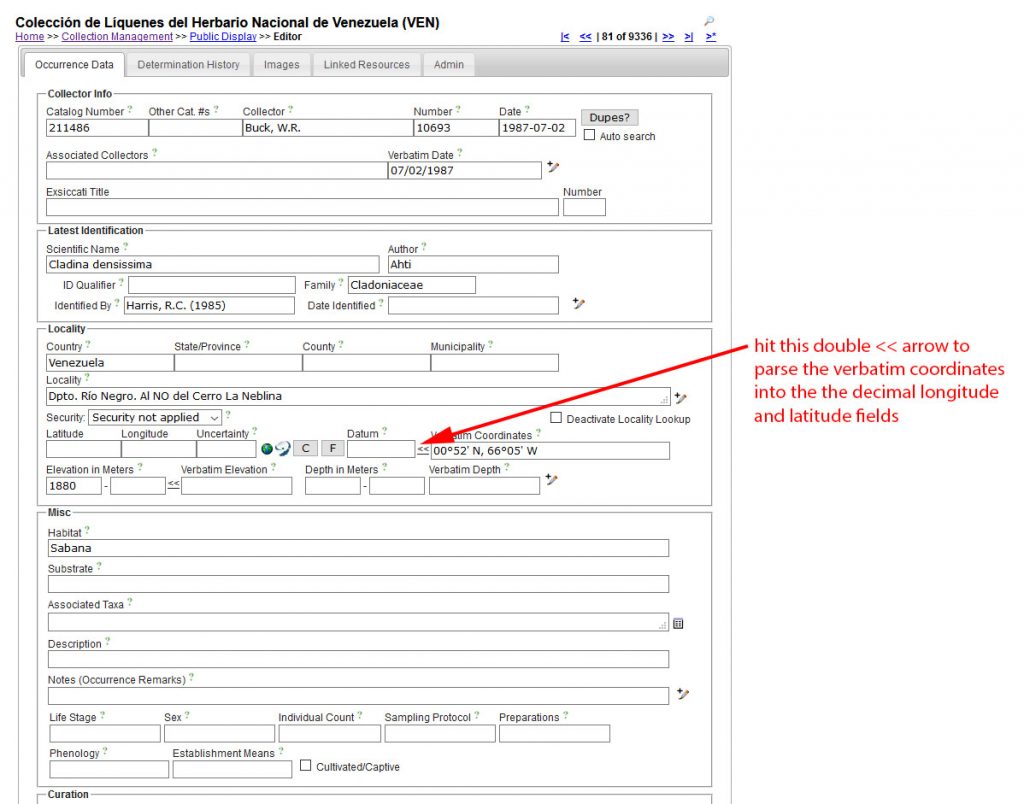
Unless you want to parse the data manually for each record, it is therefore important to adjust your spreadsheet for some of these fields before the upload.
Finally:
Before you go, one important notice. Generally all your taxon names in the identification field will be uploaded, even names not (yet) included in CNALH’s taxonomic Thesaurus. You may want to review the Tutorial on the Taxonomic Name Cleaner and routinely use it after having uploaded new occurrence records.
The Taxonomic Name Cleaner makes sure taxon names in your upload are spelled correctly and linked to the correct taxonomy, it also shows names not (yet) available in CNALH, which may need to be added.
